Control de incidencias operativas: de mensajes sueltos a un sistema trazable
Control de incidencias operativas de mensajes sueltos a un sistema trazable
Cuando una incidencia entra por WhatsApp, email, llamadas y se lo digo a, el problema no es falta de esfuerzo. El problema es no tener control real del estado, responsable y SLA.
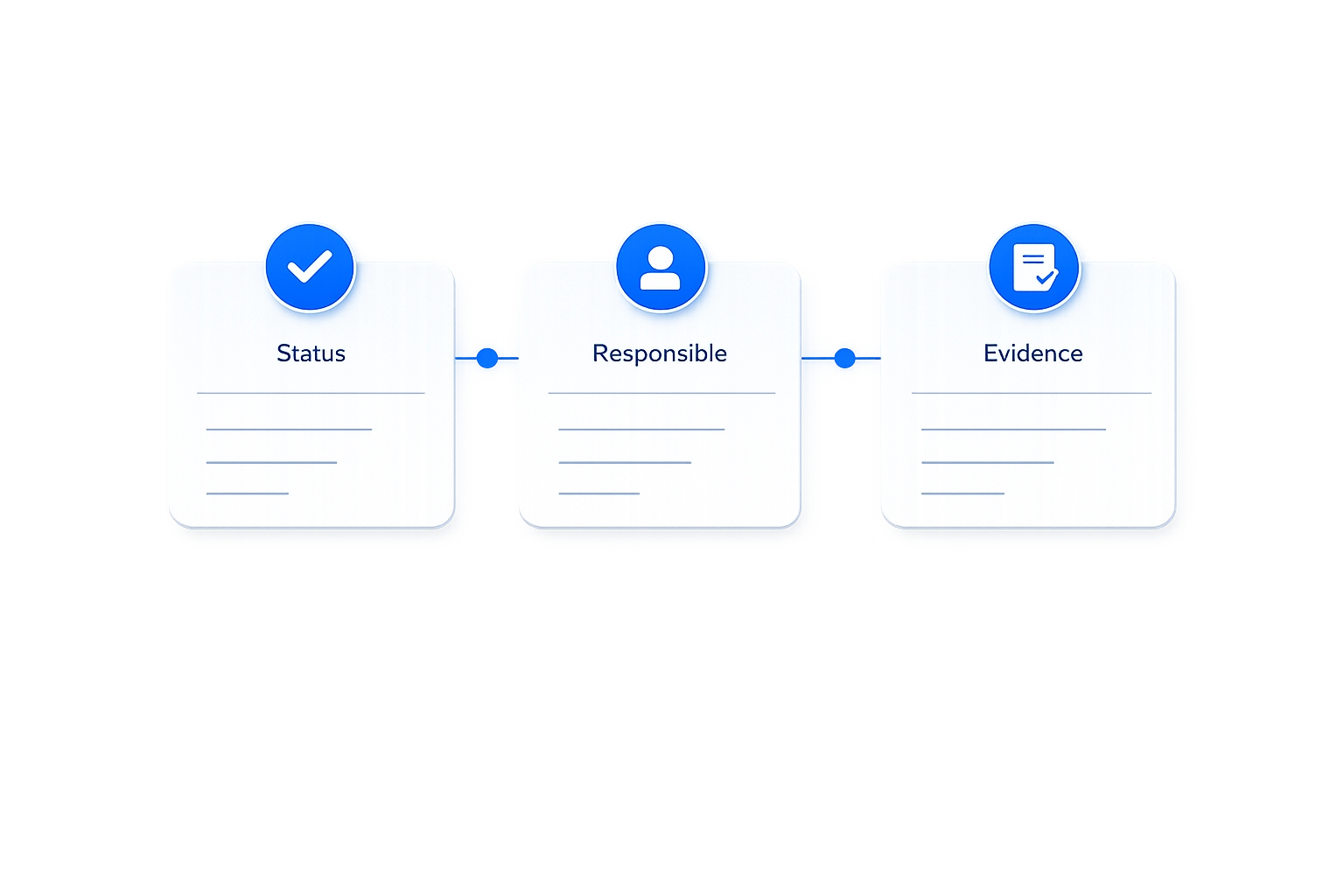
- Entrada única (registro, no conversación)
- Estados visibles por fase
- Responsable claro en cada paso
- Evidencia e histórico audit-ready
- SLA medible y gestionable
Contexto del caso (qué proceso estaba en juego)
- Tipo de operación con incidencias diarias (producción, mantenimiento, logística, calidad o backoffice)
- Volumen y urgencia con seguimiento manual, pérdida de contexto y duplicidades
- Riesgo de retrasos invisibles, dependencia de personas clave y baja trazabilidad
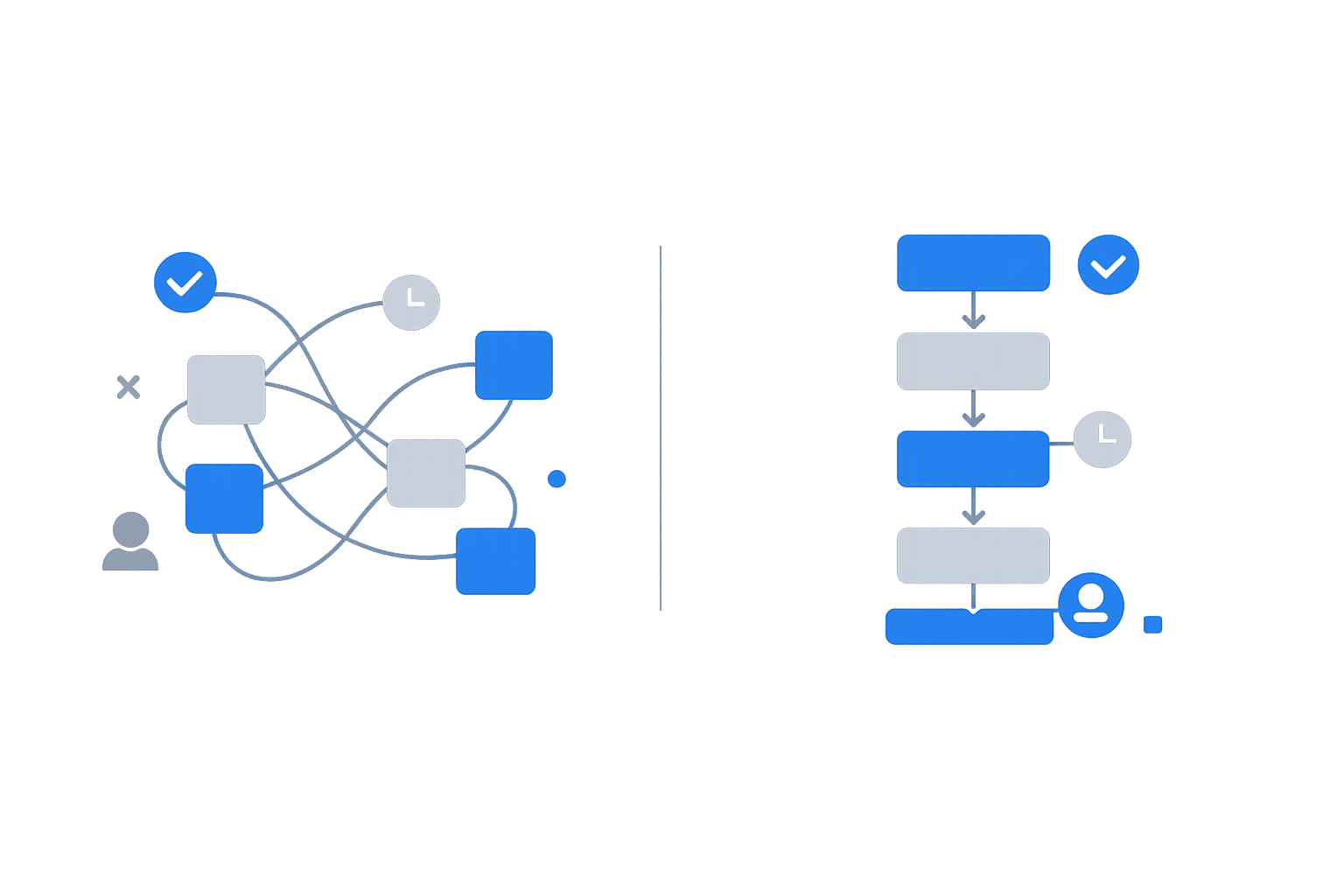
Antes incidencias dispersas igual a coste oculto y riesgo
- Incidencias en múltiples canales con verdades diferentes
- Duplicidades por falta de visibilidad de estado
- Prioridad por chat sin criterios claros
- Cambios y decisiones sin evidencia
- Seguimiento basado en persecución
- Cierre informal sin confirmación ni aprendizaje
Después incidencias bajo control
- Registro único de incidencias con ID
- Estados definidos y avance visible
- Responsable por fase con ownership
- SLA visible con alertas de riesgo
- Evidencias mínimas por incidencia
- Histórico auditable de decisiones y cambios
Diseño mínimo viable de control para incidencias
- Estados mínimos Nuevo Triado Asignado En curso Bloqueado Resuelto Cerrado
- Roles por fase solicitante triage ejecutor validador
- Reglas y excepciones para urgencias, escalado y falta de datos
- Evidencias y auditoría para decidir y defender
Método por fases aplicado (C‑O‑R‑T‑E)
PASO 1
C — Control (baseline + riesgos)
Identificar entradas actuales y fijar baseline con 2 o 3 KPIs clave.
PASO 2
O — Orden (estados, responsables, reglas)
Definir estados, responsables y reglas con prioridad simple por impacto y urgencia.
PASO 3
R — Resultado (quick win)
Implementar entrada única, estados, asignación y notificaciones para cortar persecución.
PASO 4
T — Trazabilidad (audit-ready)
Añadir evidencias mínimas, histórico exportable y control de cambios.
PASO 5
E — Evolución (escala con criterio)
Escalar con reporting y, solo si aporta valor, integraciones.
KPIs que se vuelven medibles sin inventar cifras
- Estado visible por incidencia
- Tiempo de respuesta inicial medible
- Porcentaje fuera de SLA medible y alertable
- Duplicidades reducidas por entrada única
- Reaperturas visibles y tratables
- Menos persecución por incidencia
Si te suena este antes el problema no es tu equipo
- Incidencias que se pierden en chats
- SLA no real o no visible
- Dependencia de una persona que se lo sabe
Preguntas frecuentes
¿Qué es control de incidencias operativas exactamente?
Poder responder en tiempo real qué incidencias hay, en qué estado están, quién las tiene y qué bloquea, sin perseguir por mensajes.
¿Cuáles son los estados mínimos recomendables?
Nuevo Triado Asignado En curso Bloqueado Resuelto Cerrado, ajustados al proceso real.
¿Quién debe hacer el triage?
Alguien con visión operativa para priorizar y asignar, no necesariamente quien ejecuta.
¿Qué datos mínimos debe capturar una incidencia?
Síntoma, dónde ocurre, cuándo empezó, impacto y evidencia mínima.
¿Cómo aplicar SLA sin burocracia?
Tiempos por prioridad, estado Bloqueado explícito y escalado por tiempo.
¿Se puede integrar con sistemas existentes?
Sí, cuando aporta control real. Primero flujo claro y datos mínimos; luego integración.
Empieza por un diagnóstico estratégico
En 30–45 min mapeamos el flujo real de incidencias, fijamos baseline y salís con roadmap por fases.